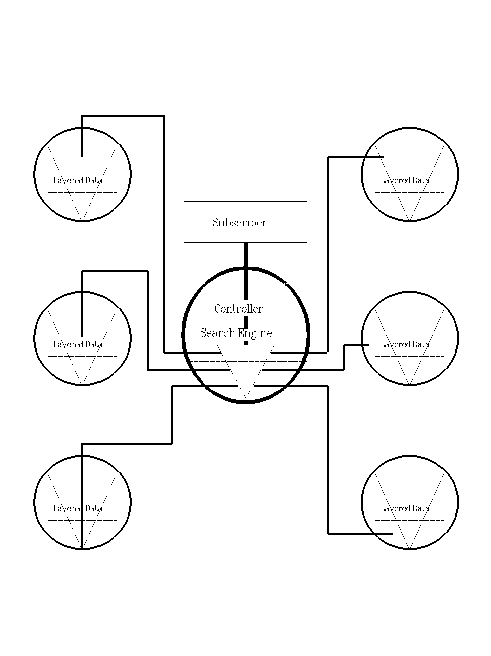
Search Mechanism Structure Possibilities
Requirements and Approaches for a Computer Vulnerability Data Archive
Carl E. Landwehr, Naval Research Laboratory
Bruce C. Gabrielson, Kaman Sciences Corp.
Jeff D. Humphrey, Kaman Sciences Corp.
1. Introduction
An archive for computer vulnerability information could benefit diverse communities, but those communities will impose different requirements on its uses and form. We use the word "archive" rather than "repository" here to imply a place to store or retrieve information, regardless of its location, structure or form.
The workshop call for papers poses a number of questions regarding repository organization, use and form. However, many of these questions are at a relatively fine level of detail (how should the repository be structured, what data items should be present, etc.). These questions cannot be answered appropriately until some larger issues are addressed, such as which communities will the repository/archive serve, how will it be supported, and how can it be controlled.
This paper considers the requirements for such a repository from the perspective of three classes of stakeholders: providers, those who provide vulnerability information to an archive, subscribers, those who retrieve information from it, and the archive manager, who is responsible for maintaining its controls.
The same individual or organization may be a member of two or even all three of these classes, but we need to distinguish the interests that arise from these different roles. After considering the range of requirements that such an archive might satisfy, we review the current situation and suggest approaches to satisfy some of those requirements.
2. Subscriber Requirements
Potential subscribers include users of systems with flaws documented in the archive, system administrators, system designers and developers, and researchers with general interests in computer security and system design and development. We consider briefly the kinds of questions members of each of these groups might pose to the archive.
All groups will want to know what the quality of the information in the archive is -- how old it is, whether it has been reviewed by anyone, whether measures in place to assure it is complete and uncorrupted, and so on.
3. Provider Requirements
Providers are those who put information into the archive. It is a given that the subscriber wants something from the archive, but why should the provider want to place information into the archive? Perhaps some dedicated individuals or groups will provide such information for the common good, but unless there is some stronger incentive, it seems unlikely that a readily available archive will remain current for long. In fact, we suspect that the providers will be drawn from the same general pool as the subscribers, but they may have different concerns as providers than they do as subscribers. Possible provider scenarios include the following:
The differences among the categories of providers seem less sharp here than those among subscribers. We might expect in general to see concerns about the distribution of the information provided (some information is to be widely distributed, other information to be closely held, or perhaps released after some delay), identification of the source of the information (I may not want it known that my system was penetrated, but I might like to have credit for finding the vulnerability or developing the fix).
4. Archive Manager Requirements
The archive manager answers to three stakeholders: those who provide informaiton to the archive, those who request informaiton from it, and those who won the computing resources on which the archive resides. The manager needs to satisfy providers that the information released will be accurately categorized and distributed, and that any release constraints that the manager agrees to enforce on behalf of the provider are correctly administered. The manager must also satisfy subscribers that the information they receive has the quality they expect of it and that they can retrieve the information they require quickly and conveniently.
If the archive resides on a particular computer system, the archive manager also needs to be able to assure the archived information owner that adequate controls are in place to limit the owner's exposure to liability; otherwise the owner is unlikely to allocate the resources to be managed.
5. Today's Situation
Repositories of vulnerability information exist today. They are organized in various ways and are typically well-protected. The repository managers are often unable to release the contents, either because of agreements they have with providers that prevent them from doing so, because they are concerned that distribution of the information could be damaging, or perhaps because they consider the information proprietary -- a corporate asset. In some cases, access to these repositories seems to be granted on the basis that you can only see what you put in, or perhaps that you can only review the database if you have something to contribute to it. Politically and commercially, organizations are reluctant to reveal security incidents and vulnerabilities openly.
6. Possible Architectures
We now consider some approaches that might be taken to establishing a more coordinated archive of computer vulnerability data than presently exists. We distinguish three possible approaches: centralized, federated, and distributed search-engine-controlled.
6.1 Centralized Database Approach
A vulnerability database would be established and administered at a single location. This approach simplifies the problems of access control, since there is only one point of entry or egress. It also focuses the issues of quality assurance and liability on a single place. However, an initial effort will be required to import information from existing archives and to bring it into a common representation format. In addition, the site will require some degree of continuing staff support for upgrading and quality assurance activities. This approach also requires the providers of the data to surrender control of it to a trusted third party; at present the provider is likely to release detailed data directly to the subscriber, if at all. Considerable power may accrue to the controller of the database.
6.2 Federated Database Approach
In this case, the repository is a federated database, so that each site retains primary control over the release of the data it currently holds, but the sites may agree to register users in common and to respond to certain queries in a consistent manner. Reformatting of existing archives would be required only to the extent that each site would have to agree to support a specified set of queries; quality assurance and maintenance costs are shared by the sites. Some central management might be required to resolve user registration, query set, and quality assurance issues.
6.3 Distributed Repository with Access Through Web-Like Search-Engines
This approach would establish an information gathering capability based on subscriber needs similar to that currently used on the Internet. Each existing site with a store of vulnerability data would determine the level of releasability for the data it holds.
Users would pose queries to a focused search engine (many examples of which are now available). This engine would locate the requested information which could also be concurrently available on the web or to restricted organizations. The information could be returned directly to the requester (depending on sensitivity) or through a set of controlled links together with a token that a subscriber might use for authentication.
In this approach, the central archive manager would only require resources to control the search engine capabilities, handle subscriber administration, and verify quality assurance of the information provided. Each subscriber organization would be required to change little of the way it is structured or how it currently changes the information in its own archive. This approach could also allow different sites to specialize in information about vulnerabilities of different systems (e.g., each manufacturer maintains a site for current vulnerability information on its products) while maintaining a relatively straightforward and common path for accessing that information.
6.3.1 Search Engine Configuration
Two immediate possibilities exist for a potential search engine.
In either case, there is the possibility of protecting the link itself during a file exchange using encryption if necessary.
The figure shows a number of logistical possibilities based on the level of access granted to the user.
Search Mechanism Structure Possibilities
7.0 Access Rights to the Vulnerability Data
This subject is politically charged and could be the most difficult problem to resolve. Basically, certain assumptions are made on the archive information base.
Given the above, any attempt at creating a vulnerability repository wherein the pool of subscribers consist of "haves" and "have nots" could be seriously flawed from the onset. However, the possibility of a real world solution to this dilemma may exist.
For any system to be both effective and successful, it must be based on real world value. That is, those individuals and organizations who have real data that others desire are in a high position in the system based on their "merit" in the system, and those individuals and organizations who only want to take from the system are in a lower (less powerful) position.
This condition represents a real world micro-economy in which those individuals and organizations who have data of value to the system are the "sellers" and those who are only interested in accessing that data are the "buyers". Most individuals and organizations will fit both profiles at various times (we all provide and take depending on what we're doing).
Thus, one suggestion for controlling access to the vulnerability information is simply a merit based economy in which users gain "potential" or value in the system (cash) based on their ability to "sell" information to the system, and cash "spend" their acquired value to retrieve like data from the search system.
An advantage of this system is that if an organization feels that they wish to sponsor another individual or organization's research by providing access to the system, it is simply a matter of transferring their acquired value to that individual or organization so that they might have access to the data they require.
Merit based systems equate well to real world economics of buyers and sellers and transcend political boundaries between organizations adding value to the "system" as opposed to decreasing value through access policy and politics.
8. Summary and Conclusions
This paper attempts to place the creation of a repository for vulnerability information into a "real world" context. Making such information available to those who have immediate and serious needs is certainly a worthwhile goal requiring serious support. However, making the structure work in a way acceptable to all who currently control their own information sources is difficult at best.
Several possible perspectives and suggestions are presented. The goals of a workshop are to consider many approaches. Each approach should be considered based on how workable it is in relation to available resources, existing structures, and the needs of those who will use it.